
치춘짱베리굿나이스
indexedDB 본문
indexedDB

개인적으로 JLPT 공부를 위한 단어장 어플리케이션을 구상하면서, 단어를 저장할 수단을 고민하다가 브라우저별로 따로 저장할 수 있고, 로컬 스토리지보다 많은 양의 데이터를 담을 수 있는 Indexed DB 에 관해 공부해보기로 했다
- json에 단어를 전부 저장해서 프론트엔드 코드 폴더에 저장한 뒤 불러오는 방식은 깃에 코드를 계속 올리다 보니 교재 저작권에 위배될 가능성이 있다고 느꼈다
- 서버를 만들어서 운용하기엔, 유저별로 다른 데이터를 보여주고 싶다면 회원 기능까지 구현해야 하기 때문에 생각보다 덩치가 너무 커질 것 같았다
- 그렇다고 회원 기능 없이 하나의 데이터베이스를 모두가 접근하게 하면 마찬가지로 저작권 이슈가 생길 가능성이 있고, 혹여나 (정말 혹시나!) 내 어플리케이션을 쓰고 싶어하는 사람은 다른 단어를 추가하고 싶어할 수도 있기 때문에…
- 로컬 스토리지는 10메가정도밖에 담을 수 없기 때문에 (그래도 어림잡아 400만개 단어를 저장할 수 있긴 하다) IOS 기준 500메가 이상으로 더 넉넉한 indexedDB를 이용해보기로 했다
MDN에서의 서술
IndexedDB는 파일이나 블롭 등 많은 양의 구조화된 데이터를 클라이언트에 저장하기 위한 로우 레벨 API입니다. IndexedDB API는 인덱스를 사용해 데이터를 고성능으로 탐색할 수 있습니다. Web Storage는 적은 양의 데이터를 저장하는데 유용하지만 많은 양의 구조화된 데이터에는 적합하지 않은데, 이런 상황에서 IndexedDB를 사용할 수 있습니다. 이 페이지는 MDN에서 IndexedDB에 대한 내용을 다루는 시작 문서로 전체 API 참고서, 사용 안내서, 세부적인 브라우저 지원 상황, 그리고 핵심 개념에 대한 설명을 제공하는 링크를 찾을 수 있습니다.설명
Web Storage (Local Storage, Session Storage) 의 한계를 뛰어넘기 (?) 위한 웹 브라우저 표준 API로, 대규모 NoSQL 데이터베이스의 형태를 띄고 있다
로컬 스토리지, 세션 스토리지와 같이 get, put, search 동작이 가능하고, 추가적으로 트랜잭션을 지원한다는 차별점이 있다
- 트랜잭션: 데이터베이스의 상태를 변화시키기 위해 수행하는 작업의 최소 단위
- indexedDB에서의 트랜잭션은 데이터베이스에 접근할 때마다 발생하는 작업이라고 생각하면 된다
indexedDB는 SQL을 사용하는 관계형 데이터베이스 (RDBMS) 처럼 트랜잭션을 사용하지만, 데이터 저장 방식이 고정된 컬럼을 가진 관계형 테이블이 아닌 인덱스가 포함된 JSON 형식의 객체 기반이라는 차이점이 있다
원래 WebSQL이라고 관계형 데이터베이스를 지향하던 녀석이 따로 있었는데 어느샌가 Deprecated 되고 IndexedDB가 부상한 거라고 한다
특징
- 키 - 값 구조로 데이터를 관리한다
- 데이터 구조가 B-Tree로 구현되어 있다
- 트랜잭션을 이용하여 데이터를 가져오거나 업데이트한다
- 데이터의 모든 변화는 트랜잭션 내에서 이루어진다
- 모든 indexedDB 작업은 비동기로 이루어진다
- 관계지향 데이터베이스가 아니다 (객체지향적이다)
- 관계형 데이터베이스와 다르게 자바스크립트의 객체를 저장소에 저장하며, 각 객체는 데이터 조회를 빠르게 도와주는 인덱스 컬렉션을 갖는다
- 따라서 SQL문도 사용하지 않는다 = NoSQL (쿼리를 사용하긴 하지만, SQL은 아니다)
same-origin정책을 따른다 (CORS 때 그거다)- 따라서 한 도메인에서 저장된 데이터는 다른 도메인에서 접근이 불가능하다
장점
- 인덱스 기반으로 데이터를 찾기 때문에 매우 빠르다
- 많은 양의 데이터를 저장할 때 아주 유용하다
- 용량 제한은 없으나, 하드 디스크 상태 및 브라우저에 따라 제약이 있긴 하다
- 크롬과 엣지는 사용자 디스크 용량의 60%, 파이어폭스는 디스크의 빈 공간의 50%, 사파리는 1기가까지 저장이 가능하다
- 무조건 문자열 형태로만 저장하던 로컬 스토리지와 다르게, 자바스크립트의 객체 자료형을 그대로 사용할 수 있다
- 당연하지만, 오프라인에서도 동작한다
- 대규모 데이터 저장이 필요하면서 지속적인 인터넷 연결을 필요로 하지 않는 작업에 효과적이다
- 내가 만들려는 것과 정확히 부합한다
단점
- 쿠키나 로컬 스토리지, 세션 스토리지 등보다 사용하기 훨씬 까다롭고 복잡하다
- 모든 브라우저에서 지원하지 않는다
- 사용자의 장치에 데이터를 저장하기 때문에, 쿠키나 세션 등에 비해 보안적으로 위험하다
- 문자열 검색이나 서버 데이터베이스와 동기화, 국제화된 정렬 등은 지원하지 않는다
다음과 같을 때 데이터가 날아갈 수 있다
- 시크릿 브라우징
- 사용자의 요청
- 디스크 한도 초과
- 데이터가 손상되었을 때
- 기능이 호환되지 않는 변경사항이 나중에 적용될 때
알아야 할 용어
데이터베이스
indexedDB 최상단에 있는 객체로, 후술할 Object Stores를 담고 있다
Object Store (객체 저장소)
실질적으로 데이터들이 저장되는 개별적인 그릇
전통적인 관계형 DB에서의 테이블과 비슷하며 한 저장소에는 한 종류의 데이터만이 줄줄이 들어간다
예를 들어, 단어장의 단어와 유저 정보를 저장하고 싶다면? 단어 저장소와 유저 정보 저장소 2개가 필요한 것
인덱스
다른 객체 저장소에서 레코드를 찾기 위해 사용되는 특수한 형태의 객체 저장소로, referenced object store 라고도 한다
트랜잭션
데이터베이스의 무결성을 보장하는, 작업 또는 작업 모음을 감싸는 최소 단위이다
트랜잭션 내의 작업 중 하나라도 실패한다면 트랜잭션 전체의 작업이 취소되며, 데이터베이스는 트랜잭션이 실행되기 전의 상태로 돌아간다
indexedDB 내에서의 모든 읽기, 쓰기 작업은 트랜잭션 내에서 수행되어야 한다
트랜잭션은 하나의 읽기 - 수정 - 쓰기 작업들이 다른 스레드에서 수행되는 데이터베이스 작업과 충돌할 염려를 줄여준다
사용방법
MDN의 용례를 정리해 보았다
다만 아래에서도 서술할 크나큰 단점이 있기 때문에 (사실상 여기 예시로는 작성이 조금 힘들다) 필자는 다른 방법으로 데이터를 다뤄 주었다
indexedDB 사용 가능 여부 판정
const indexedDB = window.indexedDB;
if (!indexedDB) {
window.alert("해당 브라우저에서는 Indexed DB를 지원하지 않습니다.");
return;
}window.indexedDB 를 이용하여 indexedDB API를 호출할 수 있다
만약 window 객체에 indexedDB가 존재하지 않는다면, 해당 브라우저에서는 indexedDB를 사용할 수 없다는 뜻이니 예외 처리를 해 주자
데이터베이스 만들기
const indexedDB = window.indexedDB;
const request = indexedDB.open("DB이름"); // 데이터베이스 이름단어장 DB를 생성해 보자
indexedDB 객체의 open 메서드를 이용하여 데이터베이스를 열 수 있다
- 첫 번째 인자로 데이터베이스의 이름을 받는다
- 두 번째 인자로 데이터베이스의 버전을 받으며,
unsigned long long자료형임을 유념하자- 두 번째 인자는 필수 값이 아니다
- 데이터베이스 버전 번호를 높이고 싶다면 이전 버전보다 더 높은 버전 번호를 두 번째 인자로 넘겨서 열어보자
만약 데이터베이스가 존재하지 않는다면, 데이터베이스를 생성하고 연다
let db;
request.onerror = (e: Event) => {
console.log("Database error: ", e);
};
request.onsuccess = (e: Event) => {
db = request.result;
};다른 indexedDB 비동기 함수들과 다르게, open 함수는 이벤트 처리 결과가 담긴 IDBOpenDBRequest 타입의 request 객체를 반환한다
이 요청 객체를 가지고 우리는 성공 시 / 에러 발생 시의 행동을 제어할 수 있다
onerror핸들러는 에러 발생 시에 실행시킬 핸들러를 정의한다onsuccess핸들러는 데이터베이스 여는 것을 성공했을 때의 핸들러를 정의한다
보통 에러 핸들러는 사용자의 디바이스에서 본 앱의 indexedDB 접근을 비활성화했을 때 호출된다고 한다
db.onerror = (e: Event) => {
console.log("Database Error: ", e);
}또한 성공 핸들러와 다르게 에러 핸들러는 버블링되어 상위 객체로 올라가므로, 이를 위해 데이터베이스 객체에 핸들러를 추가할 수 있다
데이터베이스에 객체 저장소 추가하기
let db;
request.onupgradeneeded = (e: Event) => {
db = event.target.result;
let objectStore = db.createObjectStore("객체저장소이름", {
autoIncrement: true,
});
}위의 onsuccess, onerror와 다르게 onupgradeneeded 라는 핸들러가 있는데, 이는 새로운 데이터베이스가 생성될 때 (또는 기존 데이터베이스의 버전 번호가 높아질 때) 트리거된다
새로운 데이터베이스가 생성될 때 객체 저장소를 추가하려 하므로, onupgradeneeded 핸들러를 이용하여 작업을 수행해 보자
db는 onupgradeneeded 핸들러의 인자인 e에서 target.result (= request.result) 에 저장되어 있으며, 이를 변수로 저장해 두면 작업에 용이하다
createObjectStore 메서드는 객체 저장소를 추가하는 메서드로, 인자를 2개 받는다
- 첫 번째 인자로 객체 저장소의 이름을 받는다
- 두 번째 인자는 옵션값으로,
keyPath에는 레코드의key가 될 프로퍼티의 이름을 넣어주었다 (없으면 안해줘도 된다)autoIncrement는 해당 프로퍼티가 자동 증가하게끔 할 것인지 여부를 결정한다- 두 값이 모두 지정되지 않을 경우,
key로 사용할 인수를 매번 지정해주어야 한다
객체 저장소에 인덱스 추가하기
objectStore.createIndex("인덱스명", "keyPath명", { unique: false });앞에서 생성한 objectStore 객체의 createIndex 메서드를 이용하여 인덱스를 추가한다
- 첫 번째 인자는 인덱스의 이름이다
- 두 번째 인자는 인덱스의
keyPath이름이다 (인덱스명과 일치하게 해도 된다) - 세 번째 인자는 옵션값으로,
unique가true일 경우, 중복된 값이 들어오는 것이 허용되지 않는다
데이터 추가, 검색, 제거
let transaction = db.transaction(["객체저장소이름"], "모드");먼저 트랜잭션을 만들자
트랜잭션은 데이터베이스 객체의 transaction 메서드를 이용하여 만들며, 2개의 인자를 받는다
- 첫 번째 인자는 객체 저장소의 이름으로, 빈 배열을 넘겨줄 경우 모든 객체 저장소에 대해 트랜잭션을 적용할 수 있다
- 두 번째 인자는 읽기 권한으로,
readonly: 읽어들이기만 가능하다readwrite: 읽고 쓰기가 가능하다versionchange: 데이터베이스의 스키마나 구조를 변경할 때 사용되는 모드로,indexedDB.open메서드에version인자 (두번째 인자) 를 넣어 사용할 때 자동 적용되므로 신경쓰지 않아도 된다
이미 존재하는 객체 저장소의 레코드를 읽고 쓰기 위해서는 readonly와 readwrite 면 충분하다
이 트랜잭션에도 라이프사이클이 존재하는데, 트랜잭션을 사용하지 않은 채로 이벤트 루프로 돌아가면 트랜잭션이 비활성화되고, 트랜잭션에 요청을 넣으면 트랜잭션이 활성화된 채로 유지된다고 한다
let db = request.result;
let transaction = db.transaction(["객체저장소이름"], "readwrite");
transaction.oncomplete = (e: Event) => {
// 트랜잭션 완료 시 수행할 동작
};
transaction.onerror = (e: Event) => {
// 트랜잭션 오류 시 수행할 동작
};
let objectStore = transaction.objectStore("객체저장소이름");트랜잭션에 대한 핸들러 함수들을 정의한다
oncomplete핸들러는 트랜잭션 모두 완료 시 수행할 동작을 정의한다onerror핸들러는 트랜잭션 도중 오류 발생 시 수행할 동작을 정의한다
그리고 객체 저장소를 다시금 가져온다
const request = objectStore.add(추가할 항목);
// or
const request = objectStore.delete(삭제할 항목의 keyPath 값);
// or
const request = objectStore.get(가져올 항목의 keyPath 값);
// get 요청은 권한이 readonly여도 무방하다
request.onsuccess = (e: Event) => {
// request가 성공했을 시 수행할 동작
};
request.onerror = (e: Event) => {
// request 실패 시 수행할 동작
};실질적인 추가, 삭제, 검색은 매우 간단하다
단 삭제와 검색은 삭제 또는 검색을 원하는 항목의 keyPath 값을 알고 있어야 한다
데이터 업데이트
let objectStore = db.transaction(["객체 저장소 이름"], "readwrite").objectStore("객체 저장소 이름")
let request = objectStore.get("keyPath 값");
request.onerror = (e: Event) => {};
request.onsuccess = (e: Event) => {
let data = e.target.result;
data.[인덱스] = [변경할 값];
let requestUpdate = objectStore.put(data);
requestUpdate.onerror = (e: Event) => {};
requestUpdate.onsuccess = (e: Event) => {};
}데이터 업데이트도 간단한데, get 요청으로 필요한 데이터를 가져온 뒤 값만 바꿔서 다시 put 요청으로 넣어버리면 끝이다
위와 마찬가지로 요청이 성공, 실패했을 때 핸들러에도 적절한 예외 동작 등을 정의해 주자
put 요청은 데이터가 있으면 값을 업데이트하고, 데이터가 없으면 새로 추가하기 때문에 데이터에 중복이 있을 시 트랜잭션이 중단되어 버리는 add 와 달리 중복이 존재해도 값을 덮어씌우는 방식으로 안전하게 작업을 마칠 수 있다
커서
let objectStore = db.transaction(["객체 저장소 이름"], "readwrite").objectStore("객체 저장소 이름")
objectStore.openCursor().onsuccess = (e: Event) => {
// event.target.result 에 커서가 담긴다
let cursor = event.target.result;
if (cursor) {
// 순회할 동작 정의
cursor.continue(); // 다음 목록으로 넘어감
} else {
// 커서 없음, 목록의 끝에 도달
}
}커서를 이용하면 객체 저장소 내의 항목들을 탐색할 수 있다
커서는 객체 저장소 객체의 openCursor 메서드를 이용하며, onsuccess 핸들러 내에서 cursor.continue() 를 이용하여 데이터 순회를 할 수 있다
// 해당 값 단 하나만 조회
let singleKeyRange = IDBKeyRange.only("값");
// '값'을 포함한, '값' 이후의 모든 값을 조회
let lowerBoundKeyRange = IDBKeyRange.lowerBound("값");
// '값'을 제외한, '값' 이후의 모든 값을 조회
let lowerBoundOpenKeyRange = IDBKeyRange.lowerBound("값", true);
// '값'을 포함한, '값' 이전의 모든 값을 조회
let upperBoundKeyRange = IDBKeyRange.upperBound("값");
// '값'을 제외한, '값' 이전의 모든 값을 조회
let upperBoundOpenKeyRange = IDBKeyRange.upperBound("값", true);
// '값2'를 제외한, 값1, 값2 사이의 모든 값을 조회
let boundOpenKeyRange = IDBKeyRange.bound("값1", "값2", true, false);
objectStore.openCursor(bound, "prev").onsuccess = (e: Event) => {
// event.target.result 에 커서가 담긴다
let cursor = event.target.result;
if (cursor) {
// 순회할 동작 정의
cursor.continue(); // 다음 목록으로 넘어감
} else {
// 커서 없음, 목록의 끝에 도달
}
}openCursor()메서드의 첫 번째 인자로 키 범위 객체를 넘김으로서 커서의 범위를 특정할 수 있다openCursor()메서드의 두 번째 인자로 커서의 방향 (이전, 이후) 을 조작할 수 있으며, 기본값은next이다- 유일한 값들만 순회하고 싶다면
prevunique또는nextunique를 사용한다
- 유일한 값들만 순회하고 싶다면
인덱스로 데이터 찾기
let index = objectStore.index("인덱스명");
index.get("인덱스에 해당하는 항목명").onsuccess = (e: Event) => {
// event.target.result 에 찾은 데이터가 담긴다
}
let index = objectStore.index("date");
index.get("2023-07-06").onsuccess = (e: Event) => {
// event.target.result 에 찾은 데이터가 담긴다
}인덱스 (색인) 로 데이터를 찾을 수도 있다
만약 해당하는 데이터가 여러 개일 경우, 키 값이 가장 낮은 결과 하나만 얻을 수 있다
(나머지 결과값을 가져올 방법은 일단 없다고 한다)
직접 사용해보기
문제점

사실 위의 예시들 그대로 사용하기엔 매우 큰 문제가 있다
이 API가 Promise 지원은 안 하면서 핸들러를 이용한 원시적인 방식으로 비동기 동작을 하기 때문에 직접 Promise로 감싸 ES6 형태의 비동기로 만들어줘야 사용이 간편해진다
데이터를 받아오고 싶을 때 result 를 아무데서나 함부로 받아왔다가는 위처럼 “데이터 처리 끝나지도 않았는데 result를 왜 받아가?” 라는 뜻의 에러를 마주하게 된다
결국 우리는 onsuccess 핸들러 안에서만 result 반환값을 사용할 수 있다는 건데, 그러면 코드를 작성할 때 굉장히 많은 제약사항이 생겨버린다
Promise의 도입
const dbPromise = new Promise<IDBDatabase>((resolve, reject) => {
const indexedDB = window.indexedDB;
if (!indexedDB) {
window.alert("해당 브라우저에서는 Indexed DB를 지원하지 않습니다.");
reject("Indexed DB is not supported");
}
const request = indexedDB.open("데이터베이스명");
request.onsuccess = function () {
resolve(request.result); // resolve 시에 request.result = IDBDatabase = 데이터베이스 객체를 넘겨준다
};
request.onerror = function () {
reject(request.error); // reject 시에는 발생한 에러를 반환한다
};
request.onupgradeneeded = function () {
const db = request.result;
const objectStore = db.createObjectStore("객체저장소명", {
autoIncrement: true,
});
objectStore.createIndex("인덱스명", "keyPath명", { unique: true });
...
}; // 여기까진 예제와 같다
});Promise의 특성 중 하나인 “resolve 시에 원하는 데이터를 다음 체인으로 넘겨줄 수 있음” 을 이용하여 데이터베이스 open 로직을 감싸주자
request.onsuccess 시에 resolve가, request.onerror 시에 reject가 되도록 하여 통상적인 비동기 로직처럼 만들어주는 것이다
또한 resolve 시에 requst.onsuccess 시점에서 처리가 완료된 request.result 객체 (여기서는 “불러오기에 성공한 데이터베이스 객체” 가 된다) 를 인자로 넣어줌으로서 다음 체인에서 받아와 사용할 수 있게 된다
마찬가지 방법으로 indexedDB가 사용 불가능한 브라우저 환경에서의 예외처리도 reject를 통해 수행해준다
async function getSomething(): Promise<number> {
return new Promise((resolve, reject) => {
dbPromise.then((db) => {
const result = db
.transaction(["객체저장소이름"], "readwrite")
.objectStore("객체저장소이름")
.count();
result.onsuccess = function () {
resolve(result.result);
};
result.onerror = function () {
reject(result.error);
};
});
});
}indexedDB API들을 호출할 때에도 onsuccess, onerror 핸들러 정의가 필요하므로 같은 방식으로 Promise로 감싸 준다
dbPromise는 위에서 정의한 데이터베이스 open Promise 이며, 해당 프라미스 체인의 반환값인 IDBDatabase 객체를 받아와 로직을 마저 수행한다
데이터베이스를 받아오는 것에 실패할 경우 reject로 가므로, dbPromise.then은 반드시 db를 받아오는 데에 성공했을 때에만 체인이 걸려 안전하게 데이터베이스에서 데이터를 가져올 수 있다
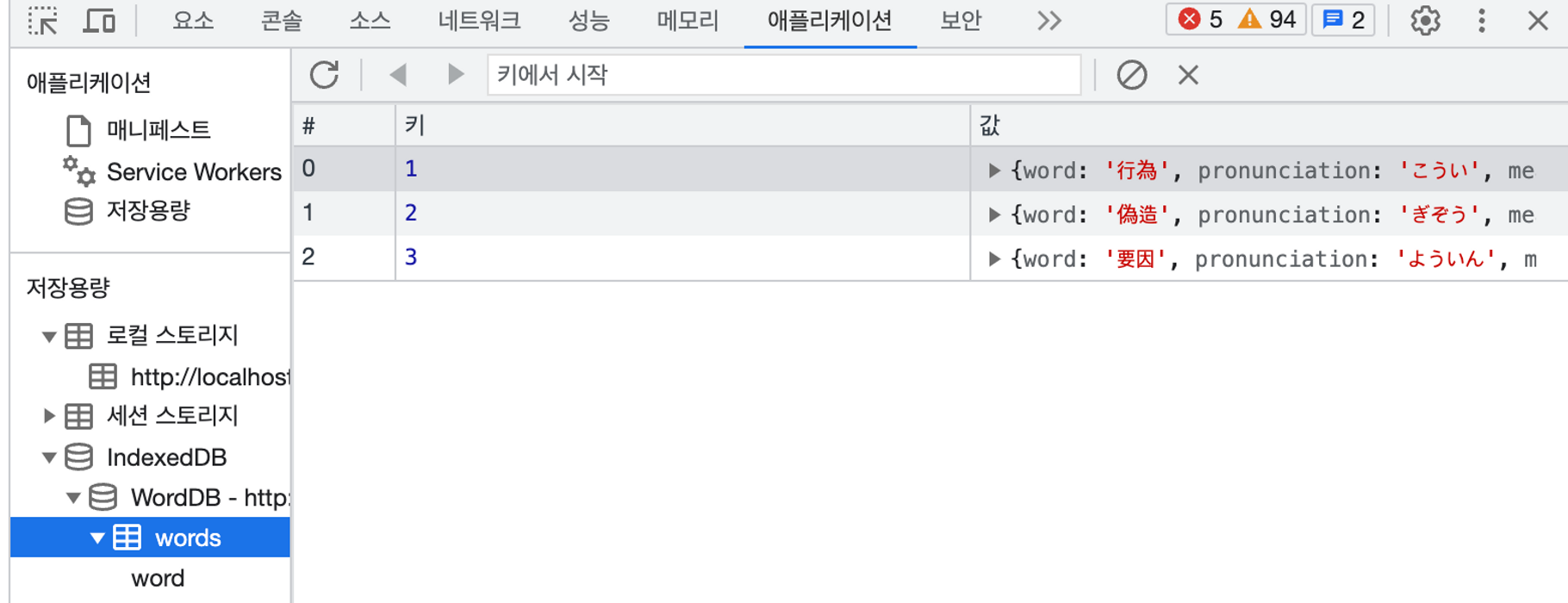
데이터베이스 접근 및 데이터 add (또는 put) 성공했을 경우 개발자 도구 - 애플리케이션 - indexedDB 탭에서 객체 저장소와 레코드들을 볼 수 있다
참고 자료
https://developer.mozilla.org/ko/docs/Web/API/IndexedDB_API/Using_IndexedDB
https://developer.mozilla.org/en-US/docs/Web/API/IndexedDB_API
https://www.blog-dreamus.com/post/indexed-db-적용기
'Javascript + Typescript > 기타' 카테고리의 다른 글
| Web Share API와 공유 기능 만들기 (0) | 2023.06.25 |
|---|---|
| localStorage / sessionStorage (0) | 2022.05.13 |
| e.currentTarget과 e.target의 차이점 (0) | 2022.05.04 |

